这是关于在代码审查中我们究竟想发现什么?系列6篇文章中的第4篇。
数据结构是编程的基本部分,这也是计算机科学专业里面一直教授的课程。然而令人吃惊的是它们依然十分容易用错。这个POST里面我们要来聊聊关于数据结构中的一些味道😇。
1. Lists
这个可能是最常见的也最常用的数据结构。因为一般情况下大家都选择它,但是有时它被用在了不该用的地方。
-
反模式:查询过多
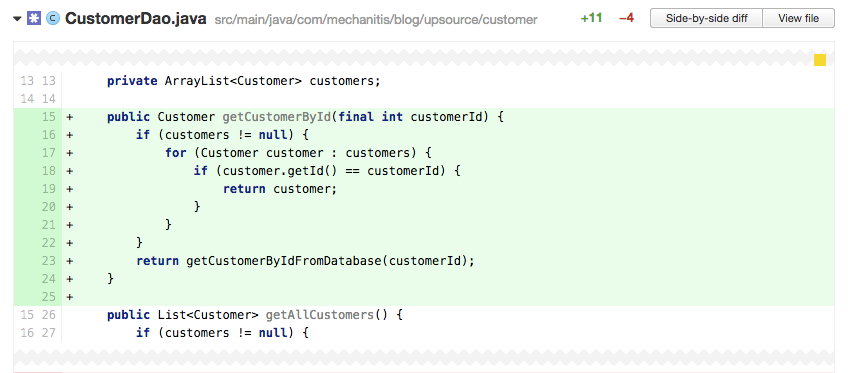
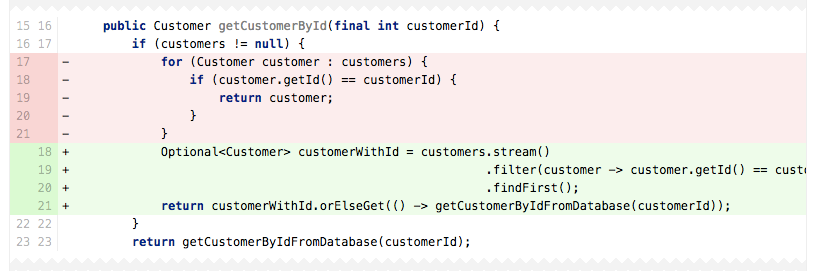
在List自己里面做迭代本身并不是件什么不好的事情。但是如果每次十分普通的操作都要迭代的话(如上面的通过ID查找客户),有更好的数据结构可以用。创建ID和客户之间的Map可能是一个更好的选择。
记住在Java8里面,语言自身支持更加表达式的查寻,这个可能不像for-loop那样明显,但是这个问题依然存在。
-
反模式:频繁的重新排序
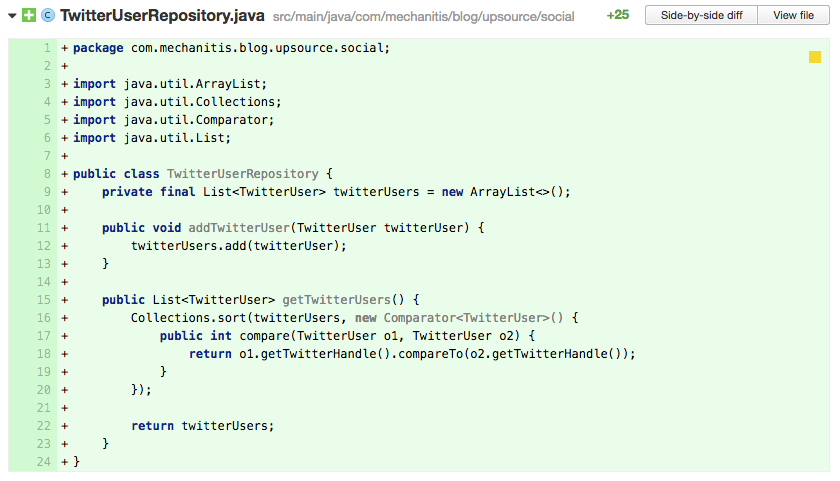
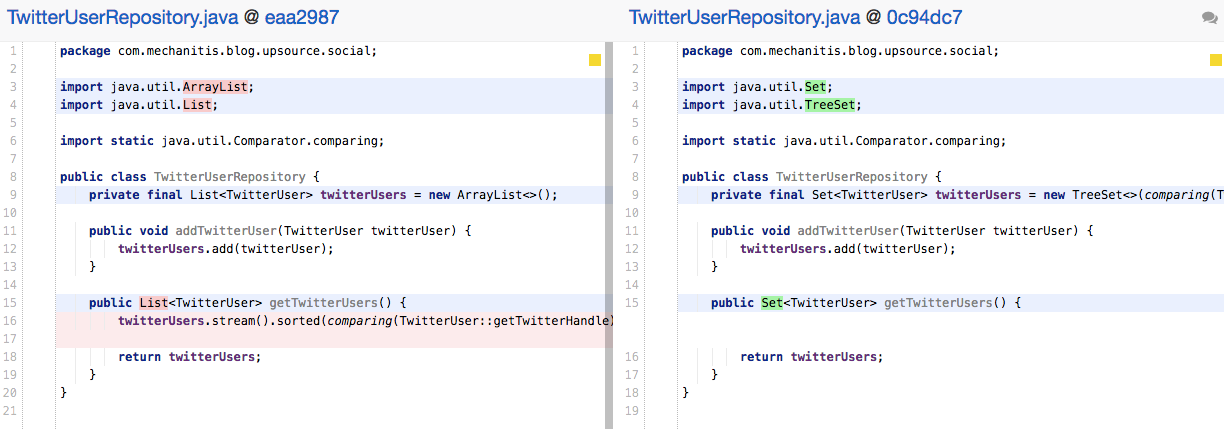
List在保持初始顺便不变的时候表现的很好,但是你可以看到上面的代码是对List做重新排序,这时reviewer需要询问List是否是正确的选择。在上面的代码16行,twitterUsers在返回之前总是要做重新排序。再说说明,Java8让这个操作看起来很容易,它尝试着去忽略这些标注:
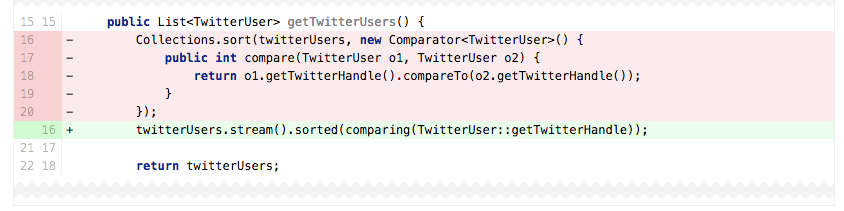
这个情况下,如果TwitterUser是唯一的,看起来你想要一个按照初始排序的集合,TreeSet看起来才是你想要的。
2. Maps
功能齐全的数据结构可以提供O(1)的访问特定元素的复杂度,只要你选中了正确的key。
-
反模式:Map用做全局常量 Map是个非常好的通用目的的数据结构,可以用一个全局可访问的map来让任何类获取它的数据。
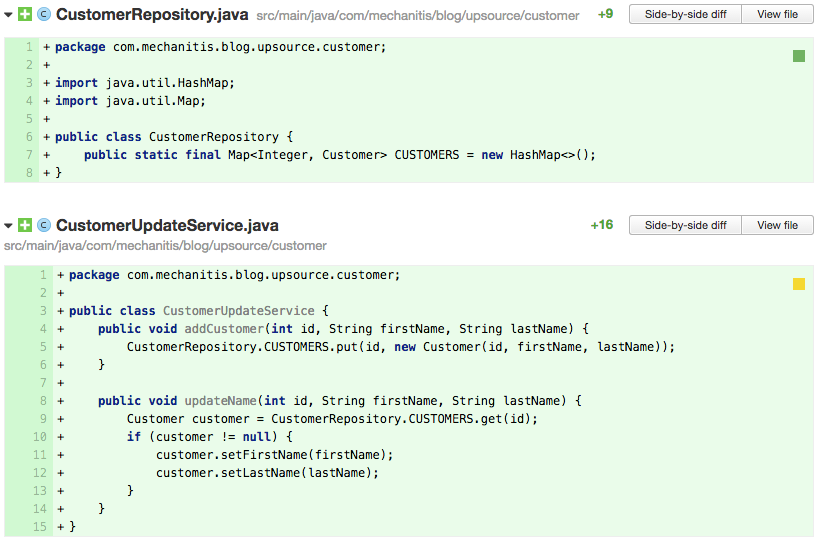
上面的代码里,作者选择简单的把CUSTOMERS map当做一个全局常量。因此CustomerUpdateService直接用这个map来做增加和更行customers操作。这个看上去并不是十分恶劣,因为CustomerUpdateService就是用来做增加和更新操作的,无论如何这些都要修改map。问题来了,当其他类,特别是这是从其他系统来的要访问这些数据的时候。
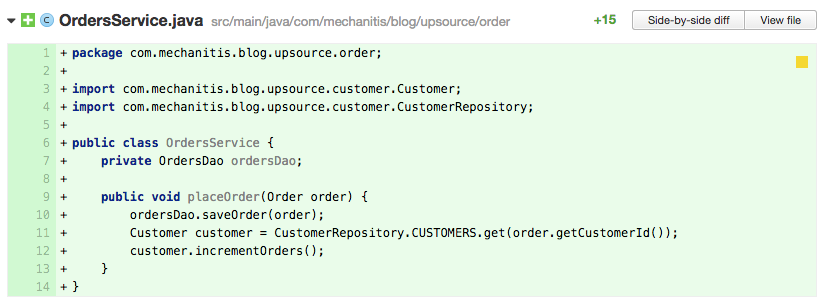
这里,order service用这个数据结构去存customer。事实上,在上面的代码里,作者犯了个错误,他们没有去检查customer是否为null,所以在12行可能会引起NullPointException。作为reviewer,你需要建议把这个数据结构隐藏起来,提供一个合适的访问方法。这样可以让其他的类更容易起理解,把复杂的map管理逻辑隐藏在CustomerRepository里面,另外,你如果在后来修改customers的数据结构,又或许转向去用一个分布式缓存或者其他技术,这些相关的修改被限定在CustomerRepository类里面,不会波及整个系统。这就是Information Hiding原则。
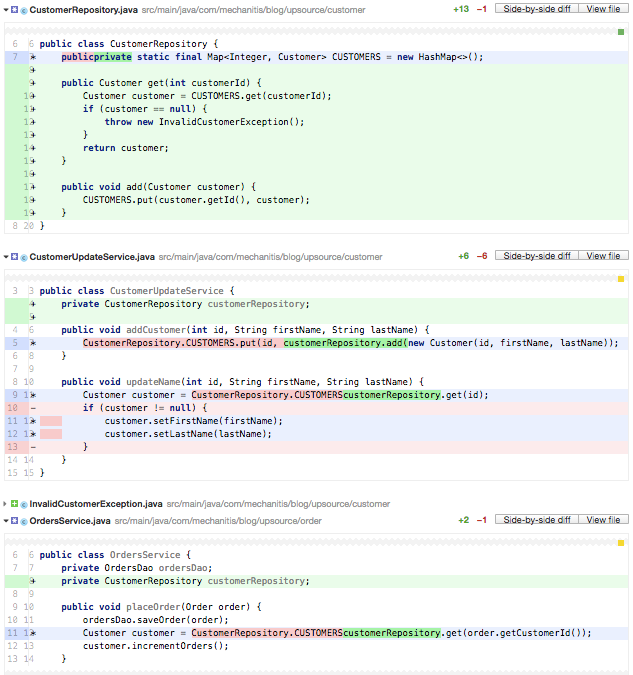
尽管修改后的代码不会变的更短,但是你将核心功能进行了标准化和集中式处理。比如,如果去取一个存在在的customer总是会给你一个Exception,后者你可以选择让这个方法返回一个新的Optional类型。
注意在code review中要去发现这个一类问题,隐藏全局变量很难做一旦在系统中到处在使用它们,但是这些问题在刚开始被引入的时候很好解决。
-
其他的反模式:迭代和重排序 和List一样,如果代码作者引入了很多排序、迭代在map里面,你可能需要建议去其他的可替代的数据结构。
-
注意Java中特有的东西 在Java里面,map的行为通常依赖于你对key和value的equals和hashCode的实现。作为reviewer,你应该去检查类中的关于key和value操作相关的方法来保证她们能得到期望的结构。
Java8中增加了需要好用的方法在Map接口里,比如getOrDefault方法可以简化上面例子中的CustomerRepository的11行。
3. Sets
经常用在底层的一个数据结构,它的长处是不包括重复的元素。
-
反模式:有时你确实不想要冗余
假设你有一个user类,用一个set来追踪用户访问了哪些website,现在有一个新功能是返回他们近期访问了哪些website。
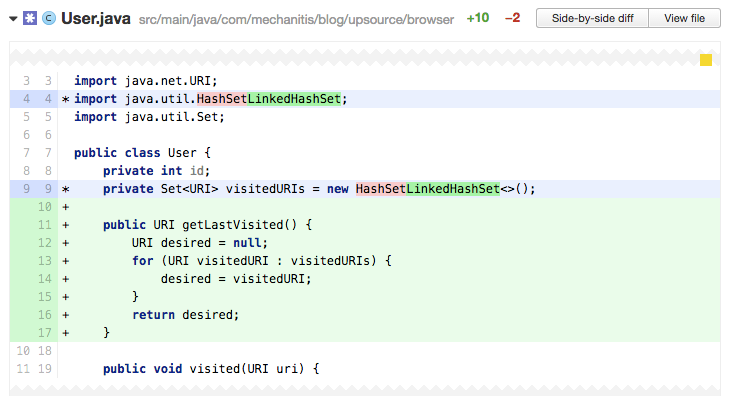
代码的作者把用来记录追踪用户访问sites的初始set从HashSet修改成LinkedHashSet,后者的实现保存了插入的次序,现在我们的set按照访问顺序记录了每一个URI。
在这段代码有好几处错误。首先,作者不得不用代价很大的变量整个set的操作去找到最后的元素(13-15行),sets不是被设计用来按位置访问元素的,这些操作lists能完美胜任。其次,因为sets不包含重复的值,也就是说如果最后一个页面在之前已经被访问过,那么在set中最后一个位置将不记录,它还是存在于之前出现的位置。
在这个case下面,stack,甚至单一字段都比用set用来访问最后一个页面都要好。
-
注意Java中的特别的东西
在Java中,set的关键操作是contains,reviewer应该检查set中针对包含操作时用到的equals的实现。
4. Stacks
Stacks是计算机科学中很受欢迎的类,然后再现实世界的情况是,它常常被忽视。在Java里面,也许是因为Stack是Vector的一种扩展,因此它会被在某种程度是认为是过时的。这里不做过于细节的讨论,只是列出两个关键点:
- Stacks支持LIFO,用于push/pop操作十分理想,用来遍历的效果不好。
- 在Java中,Deque是stack的实现,既可以用做queue,又可以当stack用,reviewer需要注意Deque的是否与要做到的场景一致。
5. Queues
另一个CS中很受欢迎的类,Queues,经常跟并发一起提起(确实,大多数实现存在于java.util.concurrent中),是用来在线程与模块之间传递数据的一种很常见的方式。
-
Queues是FIFO的数据结构,通常用来添加一个新元素到队列末,后者在队列前删除东西。Review的时候如果发现对queue的遍历(尤其是访问队列中间的元素),需要注意下对queue的使用正确与否。
-
Queues可以是有边界的也可以是无边界的。无边界的queues潜在可以无限增长,所有在review这个类型的数据结构是,看下前面关于performance的文章。有边界的queues同样也有自己的问题,在review时,需要注重什么样的条件下queue会变满,询问在它变满时对系统有什么影响。
6. Java开发者通用的注意事项
作为reviewer,你不仅要注意一些通用的数据结构的特点,还要注意它们的实现的好处与坏处。在Java 8里面,很多集合增加了新方法,要能够建设什么时候该使用新的方法代理老方法。
7. 为什么要正确的选择数据结构?
-
性能:这点大家应该都能明白,正确的数据结构的选择无疑能沟通提升性能。
-
表述期望的行为:不管是代码后继的开发者,还是你系统暴露的API的使用者来说,他们都基于数据结构做一些确定的假设。如果一个方法返回的数据是list,开发者会认为它是被排过顺序的。如果数据是存在map里面,开发者认为这里的数据会频繁的用key来做查询。如果数据是在set里面,那么它应该是只存一次不重复,这是一些很好的满足潜在约定的例子。
-
减少复杂度:对于任何开发人员,甚至是reviewer来说,他们的整体的目标应该是hi代码按照他们设想的那些来运行,并且复杂度最小。这个使得代码在将来更易读,更易理解,更易修改与维护。就像上面提到的一些反模式的错误使用,使得代码作者要写更多的代码。选择正确的数据结构一般都能够简化代码。
8. 写在最后
选择了错误的数据结构的特征:
- 在查询时对数据做了大量的变量;
- 频繁的对数据进行重新排序;
- 没有使用数据结构提供的关键方法,比如:stack的push/pop;
- 对数据结构进行读、写的代码很复杂;
另外,暴露了选择的数据结构的细节,不论是提供了全局的数据结构自身的访问,还是通过你自己类的紧耦合来操作底层的数据结构,都会倒是设计瓶颈,以后后来难以重做。最好要早点找出这些问题,而不至于在以后留下不可避免的技术债务。